三星发布 Gen5 SSD :两款 PM1743与PM9D3a的性能评测与应用优势
三星发布 Gen5 SSD :两款 PM1743与PM9D3a的性能评测与应用优势
随着大数据、云计算和5G技术的迅猛发展,对数据计算和高效存储的需求不断增加。作为全球存储设备技术的前沿供应商,三星正式发布PM9D3a固态硬盘,作为一款前沿的PCIe Gen5.0 NVMe SSD,PM9D3a为企业服务器和多核处理数据系统提供了无与伦比的性能和能效。凭借三星第八代3D V-NAND技术,PM9D3a在顺序读取和写入速度方面可分别达到12,000MB/s和6,800MB/s,其高达15.36TB的容量和多样的规格选项,确保能够满足各种数据中心的存储需求。新一代PM9D3a在提升性能的同时,通过改进的散热和电源效率设计,帮助数据中心降低运营成本,并有效应对环境挑战。这款SSD是适应AI、机器学习及大规模数据处理的理想选择,开创了数据存储的新纪元。
 全面解读RAID卡:从基础知识到品牌选择
全面解读RAID卡:从基础知识到品牌选择
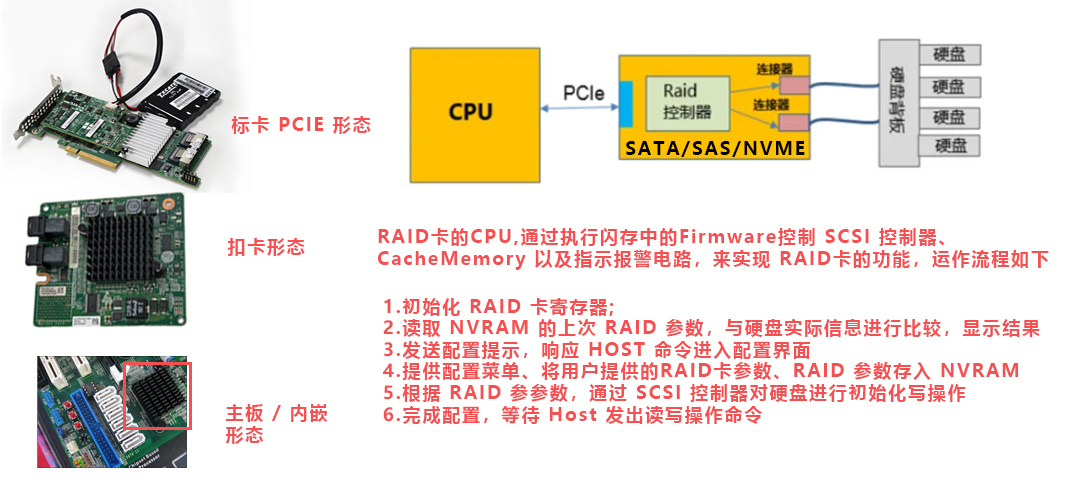
本文为您详细介绍服务器RAID卡的相关知识,包括RAID卡的基本概念、主要品牌、产品路线图、具体型号详解,以及RAID卡与服务器和硬盘的互联关系,助您更好地理解和应用RAID技术。









5G 投资和采用的步伐正在加快。根据GSMA Mobile Economy 2023报告称, 2023 年至 2030 年间,近 1 . 4 万亿美元将用于 5G 资本支出。无线电接入网络( RAN )可能占超过 60% 的支出。
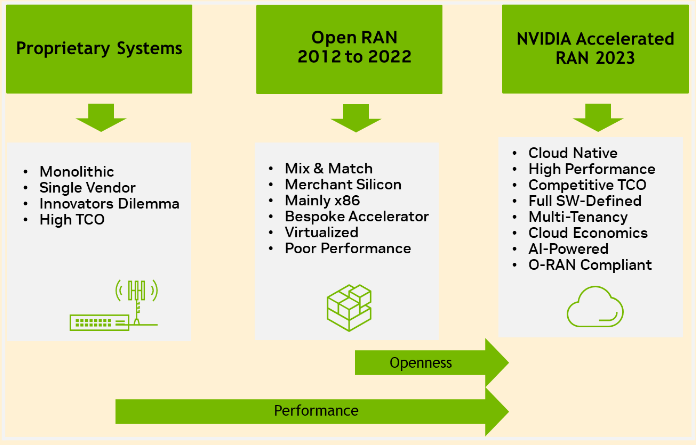
资本支出越来越多地从传统的专有硬件方法转向虚拟化 RAN ( vRAN )和开放式 RAN 架构,这些架构可以从云经济中受益,不需要专用硬件。尽管有这些好处,但开放式 RAN 的采用却举步维艰,因为现有技术尚未提供云经济的好处,而且无法同时提供高性能和灵活性。
NVIDIA 通过NVIDIA AX800 融合加速器,在可以在任何云上运行的商品硬件上提供真正的云原生和高性能加速 5G 解决方案(图 1 )。
为了从云经济中受益,RAN 的未来会在云端(云中的 RAN )。云经济之路与克莱顿·克里斯滕森在其著作创新者的困境:当新技术导致伟大的公司失败中对传统行业颠覆性创新的描述一致,也就是说,随着渐进式的改进,新的、看似劣质的产品最终能够占据市场份额。
现有的开放式 RAN 解决方案目前无法支持非 5G 工作负载,并且仍然提供较差的 5G 性能。他们大多仍在使用一次性硬件加速器。这限制了它们对电信高管的吸引力,因为传统解决方案的相对性能为 5G 提供了久经考验的部署计划。
然而,基于 NVIDIA AX800 的 NVIDIA Accelerated 5G RAN 解决方案已经克服了这些限制,目前正在提供与传统 5G 解决方案相当的性能。这为在任何公共云或电信公司边缘的商用现货( COTS )硬件上部署 5G 开放式 RAN 铺平了道路。
支持云原生 RAN 的解决方案
为了推动云原生 RAN 的广泛采用,该行业需要云原生、提供高 RAN 性能并具有人工智能能力的解决方案。
这种方法提供了更好的利用率、多用途和多租赁、更低的 TCO 和更高的自动化,具有云计算的所有优点,并受益于云经济。
一个受益于云经济的云原生网络需要彻底反思方法,以提供一个 100% 由软件定义、部署在通用硬件上并可以支持多租户的网络。因此,这不是在由云服务提供商( CSP )管理的公共或电信云中构建定制和专用系统。
需要高 RAN 性能来提供新技术,例如具有改进的频谱效率、小区密度和更高吞吐量的大规模 MIMO ,所有这些都具有改进的能量效率。事实证明,在商品硬件上实现与专用系统性能相当的高性能是一项艰巨的挑战。这是由于摩尔定律的消亡以及运行在 CPU 上的软件所实现的相对较低的性能。
因此, RAN 供应商正在构建固定功能加速器以提高 CPU 性能。这种方法导致了不灵活的解决方案,并且不能满足 Open RAN 的灵活性和开放性期望。此外,使用固定功能或一次性加速器,无法实现云经济的好处。
例如,基于 Open RAN 规范和 COTS 硬件的软件定义 5G 网络实现了约 10 Gbps 的典型峰值吞吐量,而 5G 网络的峰值吞吐量性能> 30 Gbps ,这些网络是使用定制软件和硬件以传统的垂直集成设备方法构建的。
根据最近对 52 名电信公司高管的调查Telecom Networks: Tracking the Coming xRAN Revolution,“就 xRAN 部署的障碍而言,与传统 RAN 相比, 62% 的运营商对当今的 xRAN 性能表示担忧。”
解决方案必须从基于电信网络专有实施的当前应用程序,向托管内部和外部应用程序的具有人工智能能力的基础设施发展。AI plays a role in 5G( AI-for-5G ),以实现自动化并提高系统性能。同样,人工智能与 5G ( AI-on-5G )一起发挥作用,在 5G 及其他领域实现新功能。
实现这些目标需要为云原生 RAN 提供一种新的体系结构方法,尤其是使用基于 COTS 的通用加速计算平台。这就是 NVIDIA 的重点,如图 2 所示。
重点是交付使用 NVIDIA 聚合加速器构建的通用 COTS 服务器(例如NVIDIA AX800) 可以在同一平台上支持高性能 5G 和 AI 工作负载。这将提供更好的利用率和更低的 TCO 的云经济性,以及一个可以有效运行人工智能工作负载的平台,为 6G 时代提供经得起未来考验的 RAN 。
![]()
NVIDIA AX800 融合加速器改变了 CSP 和电信公司的游戏规则,因为它将云经济带入了电信网络的运营和管理。 AX800 通过动态扩展工作负载,支持 5G 和 AI 工作负载在商品硬件上的多用途和多租赁,这些工作负载可以在任何云上运行。通过这样做,它使 CSP 和电信公司能够在 5G 和 AI 中使用相同的基础设施,并具有较高的利用率。
NVIDIA AX800 在数据中心、服务器和卡级别实现了动态扩展,支持 5G 和 AI 工作负载。这种可扩展、灵活、节能且经济高效的方法可以提供各种应用程序和服务。
在数据中心和服务器级别, NVIDIA AX800 支持动态扩展。开放式 RAN 服务和管理编排( SMO )能够实时分配和重新分配计算资源,以支持 5G 或 AI 工作负载。
在卡级别, NVIDIA AX800 支持使用NVIDIA Multi-Instance GPU( MIG ),如图 3 所示。 MIG 允许在池 GPU 硬件资源上并行处理虚拟 5G 基站和边缘 AI 应用程序。这使得每个功能能够以连贯和节能的方式在同一服务器和加速器上运行。
这种新颖的方法提供了更高的无线电容量和处理能力,有助于提高性能,并实现峰值数据吞吐量处理,为未来的天线技术进步提供了空间。

多租户动态扩展的商业意义
将 5G RAN 集中在云中(云中的 RAN )的原理很简单。 RAN 构成了电信公司最大的资本支出和运营支出(> 60% )。然而, RAN 也是最未被充分利用的资源,大多数无线电基站通常工作在 50% 以下。
将 RAN 计算转移到云计算带来了云计算的所有好处:在共享云基础设施中实现池化和更高的利用率,从而最大限度地减少了电信公司的资本支出和运营成本。它还支持云原生扩展和动态资源管理。
多租户的动态扩展在三个方面具有商业意义。首先,它能够在通用计算硬件上部署 5G 和人工智能,为在任何云上运行 5G RAN 铺平了道路,无论是在公共云上还是在电信边缘云(电信基站)上。随着所有通用计算工作负载迁移到云,很明显, RAN 的未来也将在云中。 NVIDIA 是实现这一愿景的领先行业声音,详见RAN-in-the-Cloud: Delivering Cloud Economics to 5G RAN。
其次,动态扩展利用云经济为电信网络提供 ROI 改进。与一次性解决方案的典型 TCO 挑战不同,多租户使同一基础架构能够用于多个工作负载,从而提高了利用率。
电信公司和企业已经在将云用于混合工作负载,这些工作负载对峰值敏感、成本高昂,并且由许多一次性的“孤岛”组成。同样,电信公司和公司越来越多地使用 NVIDIA GPU 服务器来加速边缘人工智能应用。 NVIDIA AX800 为使用相同的 GPU 资源加速 5G RAN 连接以及边缘 AI 应用提供了一条简单的途径。
第三,使用 NVIDIA AX800 进行动态扩展的机会为电信公司和 CSP 提供了边际效用,这些公司和 CSP 已经在投资 NVIDIA 系统和解决方案来为其人工智能(尤其是生成人工智能)服务提供动力。
目前对 NVIDIA 计算的需求,尤其是支持生成人工智能应用的需求,非常高。因此,一旦投资完成,从运行 5G 和生成人工智能应用程序中获得额外的边际效用,将大大加快 NVIDIA 加速计算的投资回报率。

NVIDIA AX800 聚合加速器在 2U 服务器上运行时可提供 36 Gbps 的吞吐量NVIDIA Aerial5G vRAN ,大大提高了软件定义的商用开放式 RAN 5G 解决方案的性能。
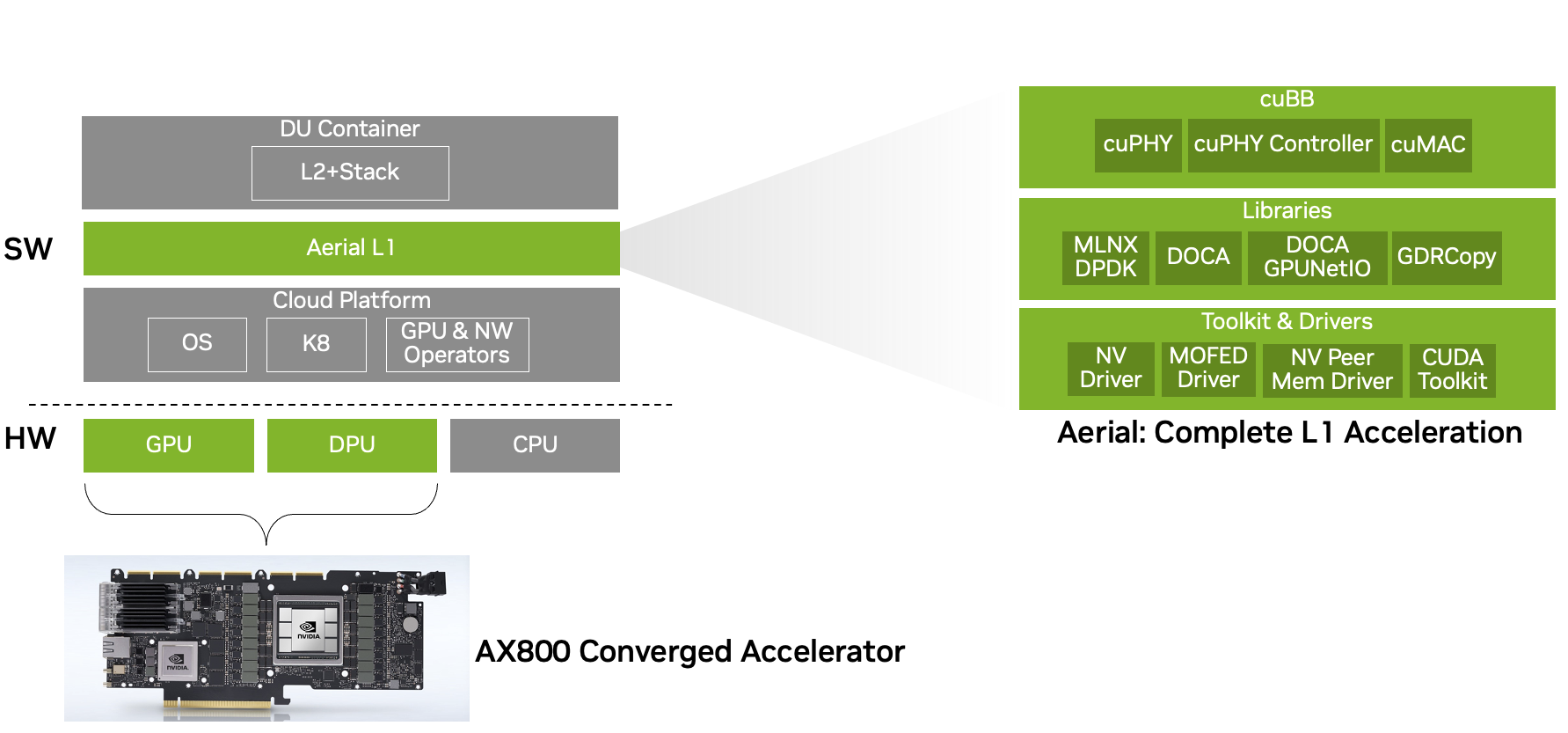
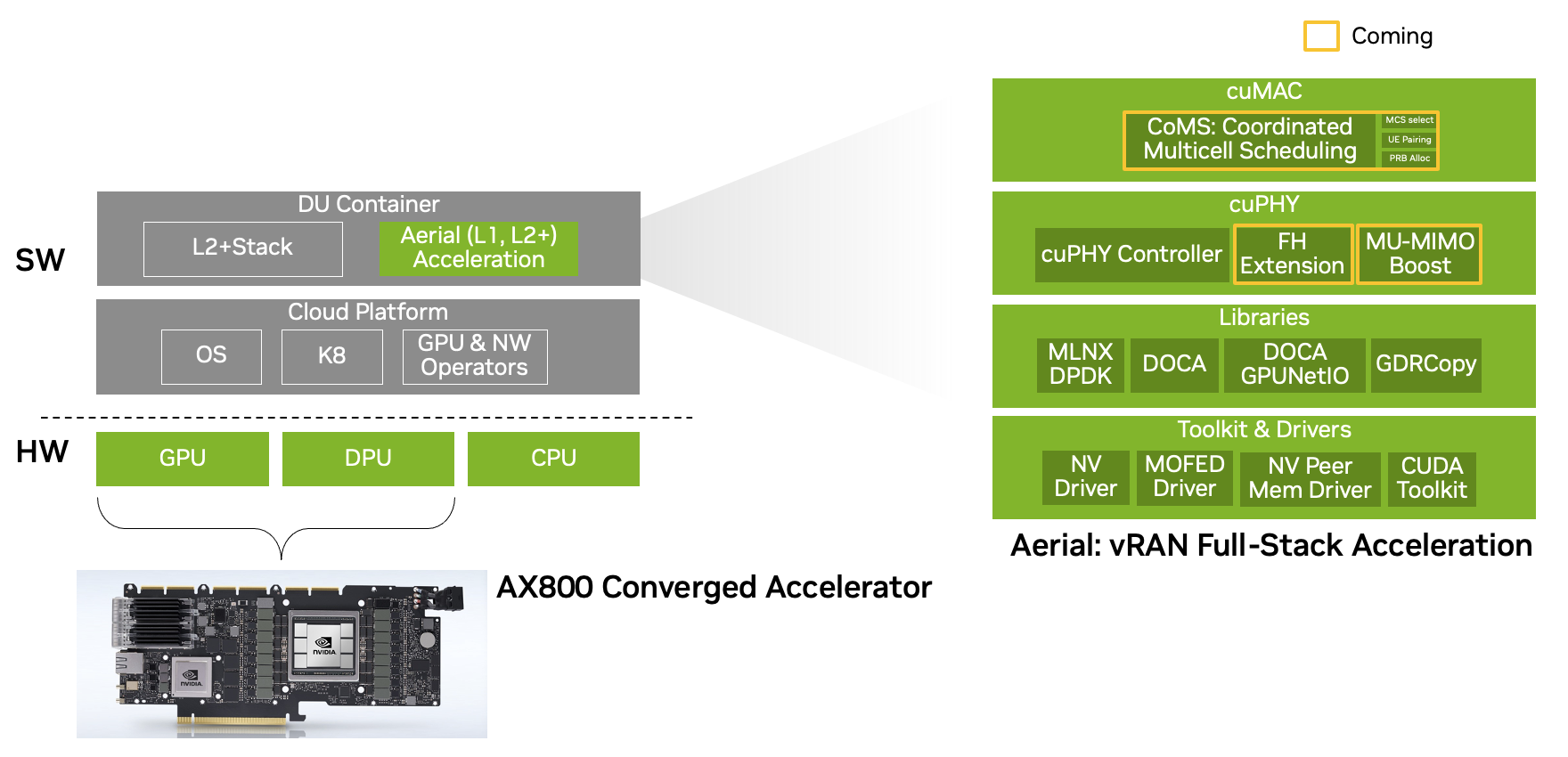
与现有 Open RAN 解决方案的典型峰值吞吐量约 10 Gbps 相比,这是一个显著的性能改进。与以传统方式构建的 5G 网络上> 30 Gbps 的峰值吞吐量性能相比,它表现出色。今天,它通过加速 NVIDIA Aerial 5G vRAN 中的物理层 1 ( L1 )堆栈实现了这一点(图 5 )。随着 NVIDIA AX800 在不久的将来可以用于整个 5G 堆栈,进一步的性能突破正在酝酿中(图 6 )。
NVIDIA AX800 融合加速器NVIDIA Ampere architectureGPU 技术与NVIDIA BlueField-3 DPU它具有接近 1TB / s 的 GPU 内存带宽,并且可以被划分为多达七个 GPU instance 。 NVIDIA BlueField -3 支持 256 个线程,使 NVIDIA AX800 能够在最苛刻的 I / O 密集型工作负载(如 L15GvRAN )上实现高性能。
NVIDIA AX800 和 NVIDIA Aerial 一起使用四个下行链路( DL )和两个上行链路( UL )层以及 100% 的物理资源块( PRB )利用率,在 100MHz 的 TDD 上为 10 峰值 4T4R 小区提供了这种性能。这使得系统能够分别实现 36 . 56Gbps 和 4 . 794Gbps 的 DL 和 UL 吞吐量。
NVIDIA 解决方案还具有高度可扩展性,可以支持从 2T2R (低于 1 GHz 的宏部署)到 64T64R (大规模 MIMO 部署)的配置。具有高层计数的大规模 MIMO 工作负载主要由用于估计和响应信道条件的算法(例如,探测参考信号信道估计器、信道均衡器、波束成形等)的计算复杂度决定
GPU ,特别是 AX800 (具有 NVIDIA Ampere 架构 GPU 最高的流式多处理器计数),提供了在中等功率范围内解决大规模 MIMO 工作负载复杂性的理想解决方案。